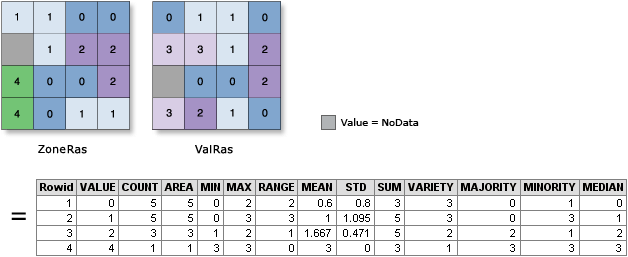
 |
| Example of using zonal statistics between grid cells (from the ArcGIS manual) |
Long version: I was hired by a customer to determine why they got unexpected results for their analyses. These analyses led to an official map with legal consequences. After investigating their whole procedure a number of issues were found. But the major source of errors was one which I found very unlikely: it turns out that the algorithm used by ArcGIS spatial analyst to determine the average grid value in a shape is wrong. Not just a little wrong. Very wrong. And no, I am not talking about the no data handling which was very wrong as well, I'm talking about how the algorithm compares vectors and rasters Interestingly, this seems to be known, as the arcgis manual states
It is recommended to only use rasters as the zone input, as it offers you greater control over the vector-to-raster conversion. This will help ensure you consistently get the expected results.So how does arcgis compare vectors and rasters? In fact one could invent a number of algorithms:
- Use the centers of the pixels and compare those to the vectors (most frequently used and fastest).
- Use the actual area of the pixels
- Use those pixels of which the majority of the area is covered by the vector.
None of these algorithm matches with the results we saw from arcgis, even though the documentation seems to suggest the first method is used. So what is happening? It seems that arcgis first converts your vector file to a raster, not necessarily in the same grid system as the grid you compare to. Then it interpolates your own grid (using an undocumented method) and then takes the average of those interpolated values if their cells match with the raster you supplied. This means pixels outside your shape can have an influence on the result. This mainly seems to occur when large areas are mapped (eg Belgium at 5m).
 |
| The average of this triangle is calculated by ArcGIS as 5.47 |
I don't understand how the market leader in GIS can do such a basic operation so wrong, and the whole search also convinced me how important it is to open the source (or at least the algorithm used) to get reproducible results. Anyway, if you are still stuck with arcgis, know that you can install SAGA GIS as a toolbox. It contains sensible algorithms to do a vector/raster intersection and they are also approximately 10 times faster than the ArcGIS versions. Or you can have a look at how Grass and QGIS implement this. All of this of course only if you consistently want to get the expected results...
And if your government also uses ArcGIS for determining taxes or other policies, perhaps they too should consider switching to a product which consistently gives the expected results.
Update March 18 2018: make sure you check out the comments from Steve Kopp (spatial analyst development team) below and the discussion - it is interesting.
For heaven's sake, I use this tool all the time....What version of ArcGIS were they using?
ReplyDeleteThe error is present in versions 10.1, 10.3 and I could also reproduce in a recent trial of arcgis pro.
ReplyDeleteI guess it is still present in more recent releases.
Note that if you click on the environments button on the bottom of the dialog, you can set at which grid the interpolation should happen, which may give you better results.
But I find that a bad practice, there is no valid reason not to use the grid system of the only grid used in the analysis.
https://community.esri.com/thread/207069-zonal-statistics-as-table-issue
A quick note: the bug is also present in version 10.4
DeleteJohan,
DeleteWe were able to reproduce your example and understand how you got that answer. However, we are also able to get the correct answer by following the recommendation in the documentation. There is not a bug in the algorithm, it uses the method described in the documentation.
As you pointed out in your explanation, the Esri documentation instructs the user to set their analysis environment to use a specific extent and snap raster. Or if you really want full control over the rasterization process to do the conversion before using zonal statistics. You did not set the snap raster.
The origin of the problem in your example is the snap raster, which sets the origin or anchor point of the corner of the output raster. Historically we had a broad set of very simple rules that were easy to understand and remember, about when properties of particular inputs would be used for deriving defaults – for example always using the first input to define the properties of the output, default extent as the minimum of the inputs, etc. Over the years as new tools were developed exceptions to these old rules have been implemented so that now it's easier to look at the usage notes for individual tools, as you did.
In this case you read the documentation but still did not succeed in getting the correct answer, which is concerning to us because it appears others may have also had this problem and not realized the solution. You make a valid point that the cell size, and snap raster could all be derived from the value raster, and we are considering making this change. As mentioned above by default extent is obtained from the intersection (MINOF) of the zone features and the value raster. And since you didn’t set a snap raster is defaulted to the origin (lower left) of that default extent.
Changes to default behavior are serious considerations which can impact any users who might be using the tool in a scripted workflow or custom application. Just as we strive to never change the signature of geoprocessing tools, we also strive to never change default behaviors without a very strong reason. So, we will weigh the benefit of making it easier to get the correct answer, against the potential impact on existing users of the tool.
For Esri customers, it's always best when you think you have found an issue like this, to contact Esri Technical Support or your local distributor. This is the fastest path to getting your issue investigated, getting the you an answer, or getting the development team to improve the software.
As for comments about performance and scalability, the zonal tools were rewritten in 10.5.1 to be faster, take advantage of multiple cores on a desktop, and run on a distributed compute cluster such as dozens of cores in Amazon or Azure.
Regarding which method is used for rasterization, it is using the cell center approach. It doesn’t look like it to you in your test because you did not set the snap raster to be the same as the value raster. It's using the lower-left corner of the input feature extent to set the origin for the output raster. If you set the snap raster and still can’t get what you think is the right answer please let me know, I’d be happy to test this against your data.
Just to summarize – ArcGIS Zonal tools do create the correct, predictable answer if you follow the recommended usage pattern in the documetation. We will evaluate changing the default behavior to make it this easier.
Steve Kopp
Esri Spatial Analyst team
Steve,
DeleteThanks for taking the time to research this. The procedure has been run by different people, and all hit the same problem. Actually, the bug has been unnoticed for several years.
I disagree with having to set a snap for getting a correct result. There is no excuse for using a different grid than the original grid. We are talking about one vector and one grid here. Why on earth would you use a different one in the default settings? And if it is not the default, why allow an option to calculate things incorrectly? There is not a single case where such a solution would be more correct.
You *should* impact existing users. If there is an impact - it means there old map is wrong. Time to fix it.
I probably should have added that the error will probably only be large if there is a large difference between values inside the raster cells and outside those cells. This was the case in our map (calculations were taking into account the rasterized vectors). In our case the impact was **huge**.
DeleteA quick note: "It's using the lower-left corner of the input feature extent to set the origin for the output raster. " - this also means that if an input feature at the left or bottom border changes, a different raster origin is used - which means that all features in the center could get different values even if their shape and corresponding grid values in the background didn't change. This probably explains a large part of the year-to-year variability we saw in the map which was unexplained so far.
DeleteJohan, regarding a few of your follow up comments...
DeleteIf you consider zonal statistics tools taking a combination of raster and vector, as a single tool without consideration for other tools and rules, then yes, using the value raster to derive default parameters would have been a better approach. However its not a single tool implemented in isolation, hence the context described above about other rules for defaults. Also mentioned above, we are evaluating changing this behavior when tools can take a combination of raster and vector input.
As for the snap raster generally, this is very important for establishing proper alignment of output rasters to minimize resampling in future analysis steps, and is especially important when one of the inputs is vector, or when two raster inputs of different alignments are combined. The overall intent is to resample data as few times as possible in an analysis workflow, preferably never, sometimes once is necessary.
There are two situations when the effect of not setting a snap raster for zonal statistics is most noticeable, when there is a large difference between nearby values as you state, and also when the output cellsize and smallest input features are close in size.
Yes, if you input a different feature dataset with similar polygons with some additional data in the lower left corner moving the origin, and do not set the snap raster, you are likely to get a different answer.
Our approach to teaching spatial analysis with ArcGIS, is to always recommend people think about and set their analysis environment at the beginning of a project before creating any new data. And as with any programming or scripting we recommend that people do not rely upon default behavior in their code, but to explicitly include whatever parameters they want to control.
For completeness: the analysis has been carried out by different people over different years (the last one a former ESRI employee).
DeleteIt seems none of them set the environment correctly to avoid the errors.
I believe one should try to design a tool in such a way that people who don't read the manual or all options (nobody does that) still gives a valid result.
This is the reason I wrote this blog post - as I want to warn people for this tool - it may give unexpected results, and its behaviour is incompletely documented (resampling).
Thanks for the alert. This explains some descrepancies I have noticed in my analyses, like totals calculated from means of zones not adding up to the same as the total area.
ReplyDeleteThat boosts my confidence to inch more close to open source GIS.
ReplyDeleteThanks for the heads up! I used the saga toolbox with weighted areas instead, much more accurate for my analysis.
ReplyDelete